




基于统计学习的检测方法

为了有效识别虚假新闻,我们实验室的小伙伴们采用了多种方法去鉴别验证。基于统计学习的检测方法是其中之一。我们收集了 2096 条来自 68 个不同网站的新闻,时间跨度为 2016 年 10 月 26 日至 11 月 25 日,这里面包含 801 条真实新闻和 1294 条虚假新闻。从新闻的众多属性中,我们挑选出 url 和文本这两个关键特征,将它们合并成新特征 “source”,然后利用 tf - idf 词向量技术处理数据。之后,我们选用 SVM、AdaBoost 等多种分类器进行测试,发现 AdaBoost 在这些分类器中表现最为出色。而它具体的测试方法在文本下方展示。

上图是分析出来的数据特征生成的统计图
首先从新闻众多属性里挑选出对鉴别真假有价值的特征,这一步至关重要。通常会选择 url 和文本这两个特征,把它们合并成新的 “source” 特征。url 能反映新闻的来源网站,可信度低的网站发布虚假新闻的概率更高;而文本内容则是直接承载新闻信息的部分,里面的用词、表述逻辑等都隐藏着真假的线索。比如,虚假新闻可能会频繁使用夸张、情绪化的词汇,逻辑上也可能存在漏洞。
用 tf - idf 词向量技术处理合并后的 “source” 特征数据。tf - idf 技术会评估一个词在一篇文档中的重要程度,简单来说,如果一个词在某篇新闻里出现的频率高,同时在其他新闻里出现的频率低,那这个词对这篇新闻就很重要。通过这种方式,把文本数据转化为计算机能理解的数值向量形式,这样就能方便后续的计算和分析了。打个比方来说,就像是给每篇新闻都贴上了独特的 “数字标签”,这些标签能精准反映新闻文本的特征。
选择合适的分类器来对处理好的数据进行分类,判断新闻的真假。常见的分类器有 SVM、AdaBoost、RandomForest、XGBoost 等。以之前的研究为例,经过测试发现 AdaBoost 的表现最为出色。不同分类器的工作原理不同,SVM 是通过寻找一个最优的分类超平面来划分数据;AdaBoost 则是通过迭代训练,不断调整样本权重,让模型更关注那些难以分类的样本。而在实际鉴别时,就像是不同的 “鉴别专家”,各自有独特的鉴别方法,但 AdaBoost 在众多 “专家” 中脱颖而出。
在实际操作中,我们可以借助 Python 中的 sklearn 库来调用这些分类器。首先要导入相关的资料包,准备好处理好的数据,然后按照不同分类器的使用方法进行设置和训练。如使用 AdaBoost 分类器,设置好相关参数,让它学习真实新闻和虚假新闻的特征模式,之后就可以用训练好的模型去鉴别新的新闻数据啦。

基于多任务学习的检测技术

除了上述方法,我们还运用了基于多任务学习的检测技术。多任务学习就像是让 AI 同时完成几个相关任务,互相借鉴经验,提升整体能力。我们使用的是 LIAR 数据集,里面有 12836 条从 PolitiFact 收集来的新闻,信息十分丰富。在这个检测模型里,我们把新闻主题分类当作辅助任务(源任务),虚假新闻检测作为主要任务(目标任务)。
模型采用深度神经网络架构,利用双向 RNN 结构(其中 GRU 发挥着重要作用)处理新闻文本,再将处理结果交给 attention 结构和后续模块。在数据处理方面,我们运用 Glove 技术 “翻译” 文本,并清洗掉无用信息。整个模型借助 tensorflow 框架和 Python 代码搭建,通过巧妙地将两个任务的损失函数相加,让模型不断优化。如果大家想要尝试的话,可以选择在实训平台上探索这个神奇的模型,感受 AI 的强大魅力。
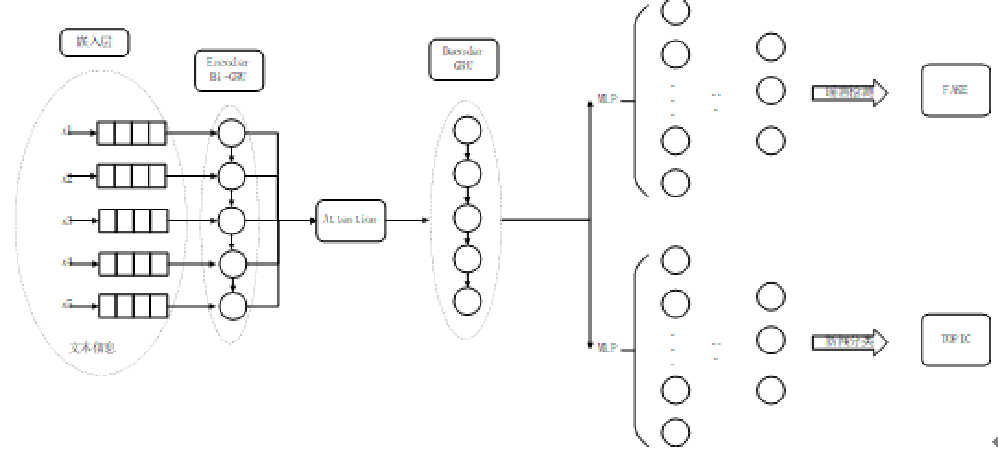
使用双向RNN结构处理输入的句子文本,使前向和后向的基本单元均为GRU,将获得的输出序列进一步传递给attention结构与后续的结构
对网络安全、人工智能感兴趣的同学欢迎过来交流学习!我们实验室经常组织各类学习交流活动,开展相关的实践项目。无论你是计算机大神,还是对 AI 充满好奇的小白,都能在这里找到属于自己的舞台。加入我们,一起探索人工智能的奥秘,为守护网络空间安全贡献自己的力量。或者你在探索过程中有任何想法或疑问,欢迎随时来实验室找我们交流,让我们携手共进,一起努力学习!
END
供稿说明
编辑丨曹宇晴、徐湘濡、刘蘅仪、梁洪嘉
审核丨谷国信